

RapidMiner Go
Automated and guided machine learning web interface.
Point/click data science for domain experts, business users and analysts – AutoML for everyone.
Access from your browser. Deliver a machine learning model & full business case in minutes.
Computationally heavy model creation is offloaded to a server, on-prem or in the cloud.
Ready…
Begin by building a new predictive model, apply an existing model to new datasets or manage deployed models and recent analyses
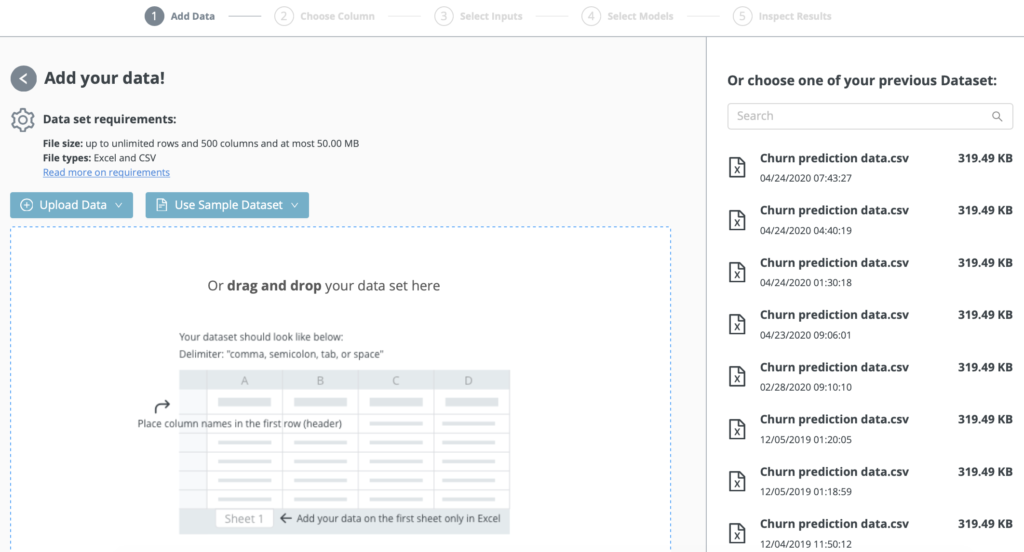
Building a new predictive model…
Upload or drag and drop your dataset
Test drive Go?
Please enter your email.
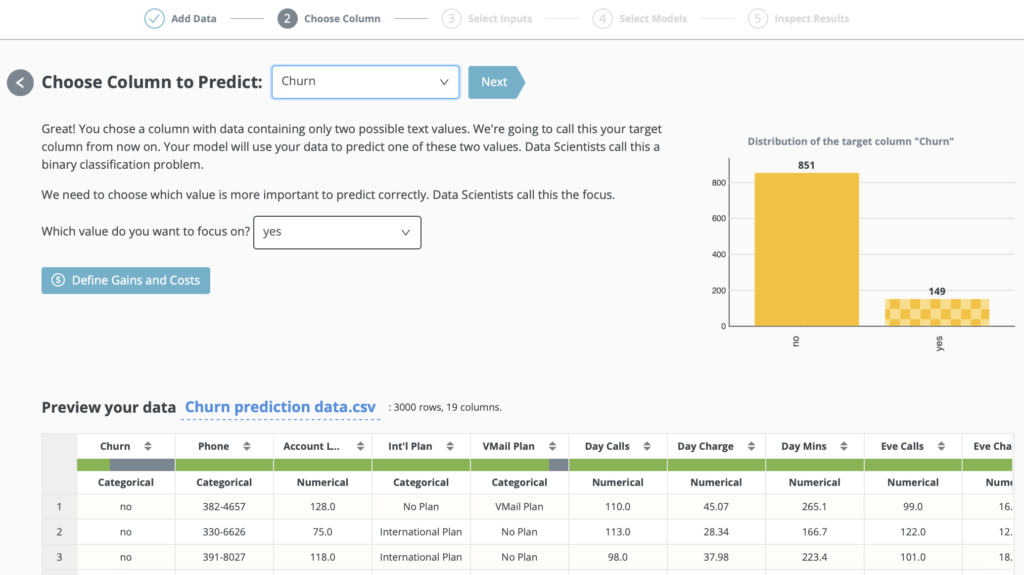
Choose the Column to Predict…
You can also optimize your model for profits & ROI, by defining gains/costs for correct/wrong predictions
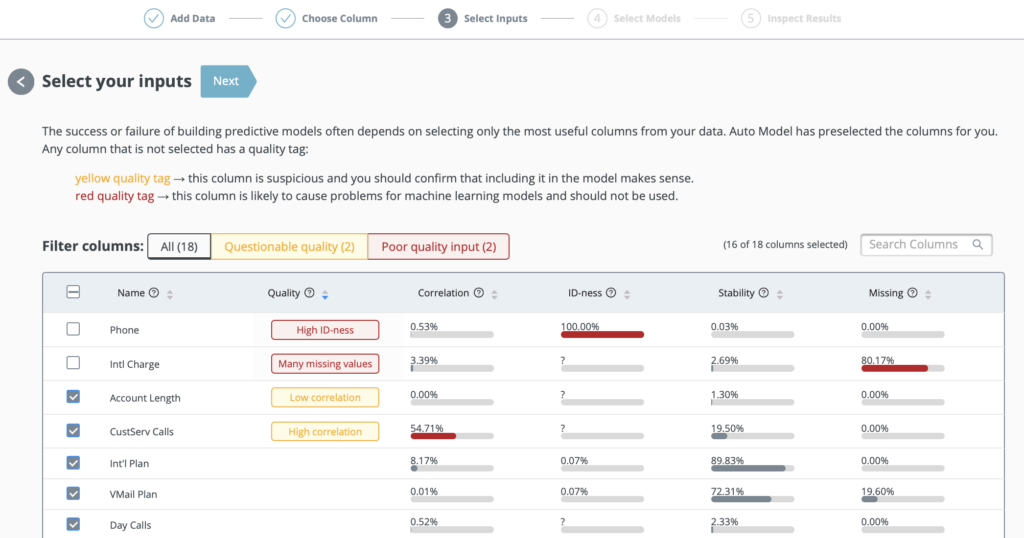
Select the input columns…Set
Successful predictive models are defined by including only the most useful input variables
Auto model feature helps here, by preselecting columns, and providing red or yellow quality tags
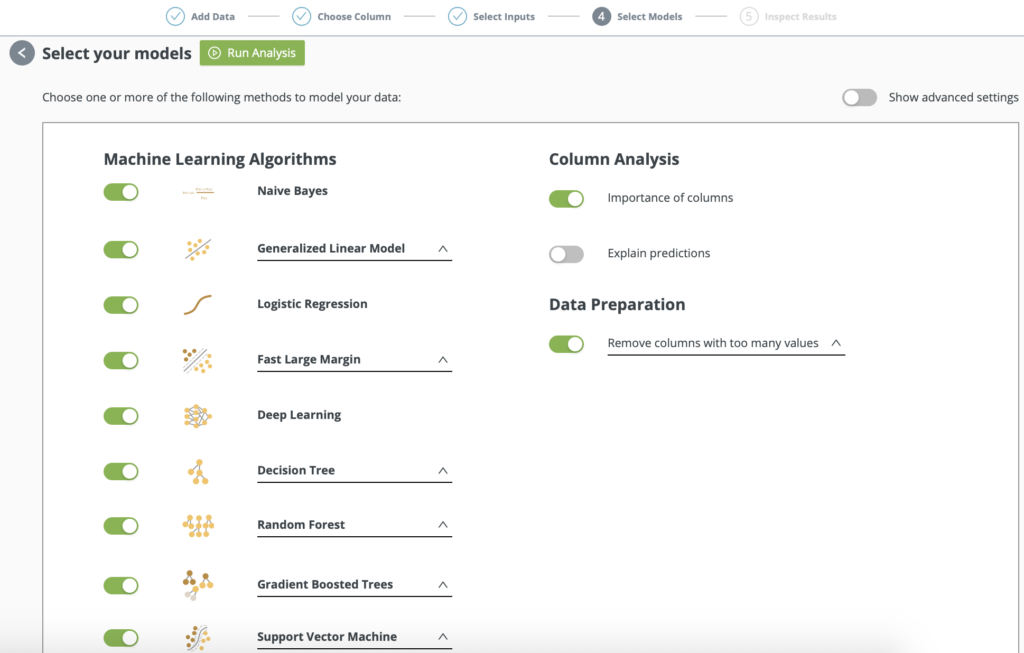
Select your models and Go…
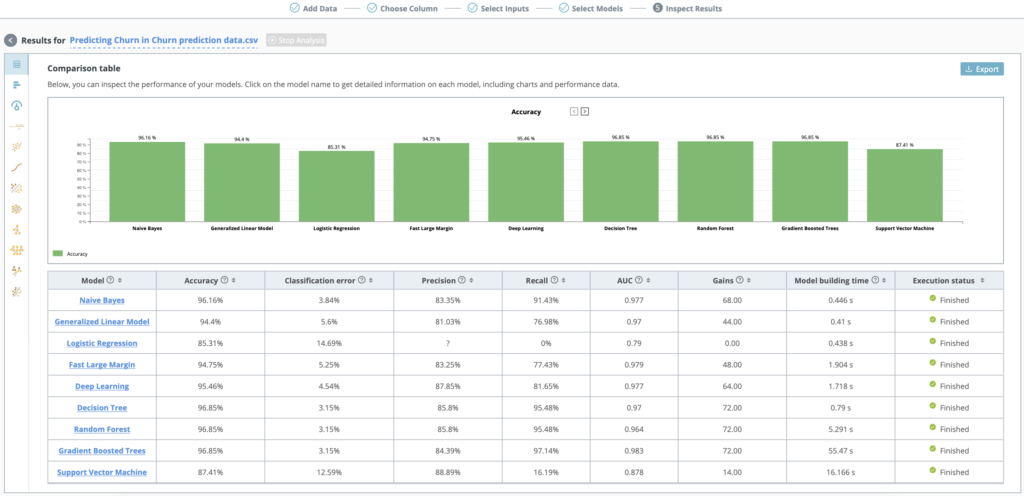
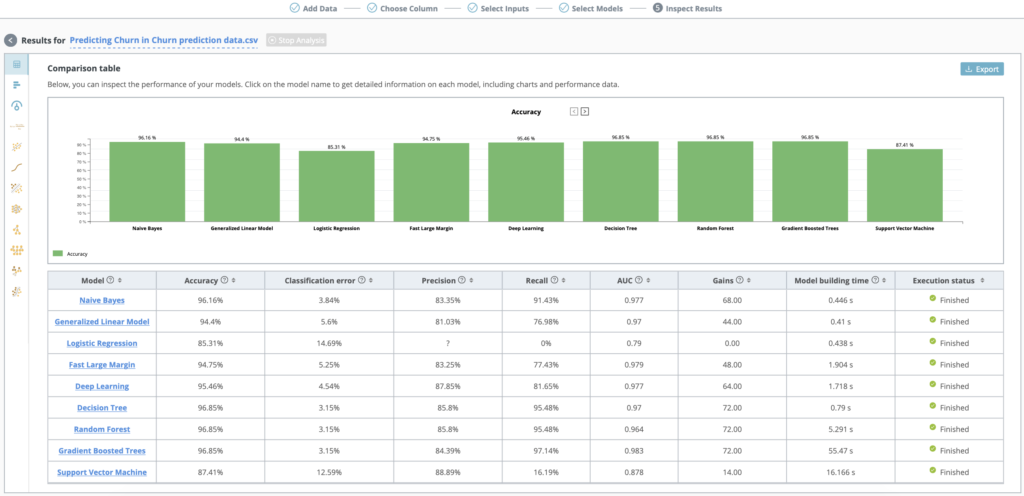
Inspect the performance of your models with the model comparison dashboard
Compare accuracy, classification error, precision, recall, AUC, accumulated benefit from cost sensitive learning and model building time.
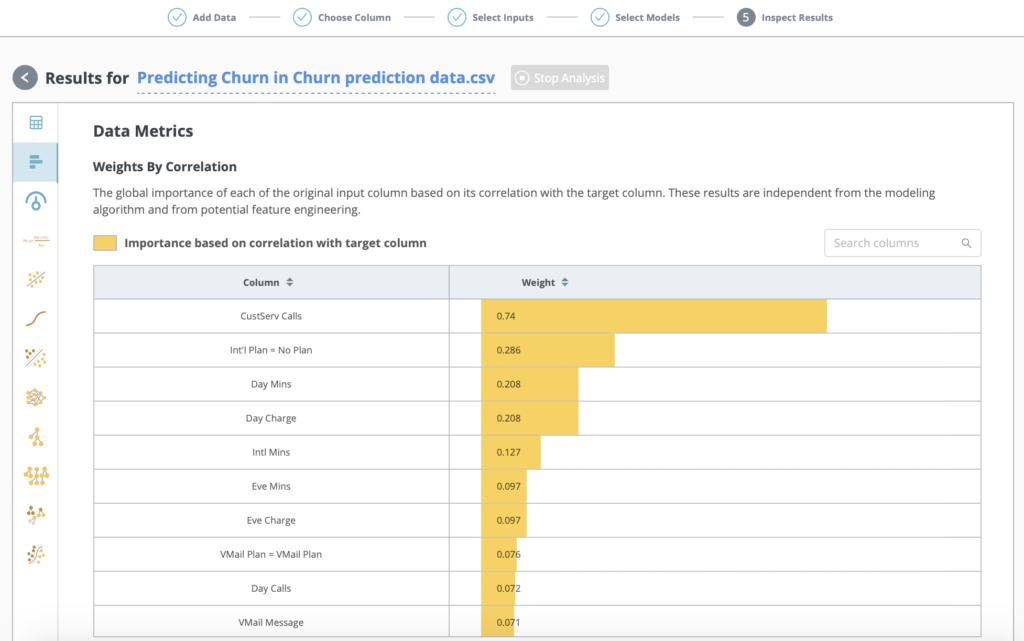
Explore the importance of each input column based on its correlation with the target column.
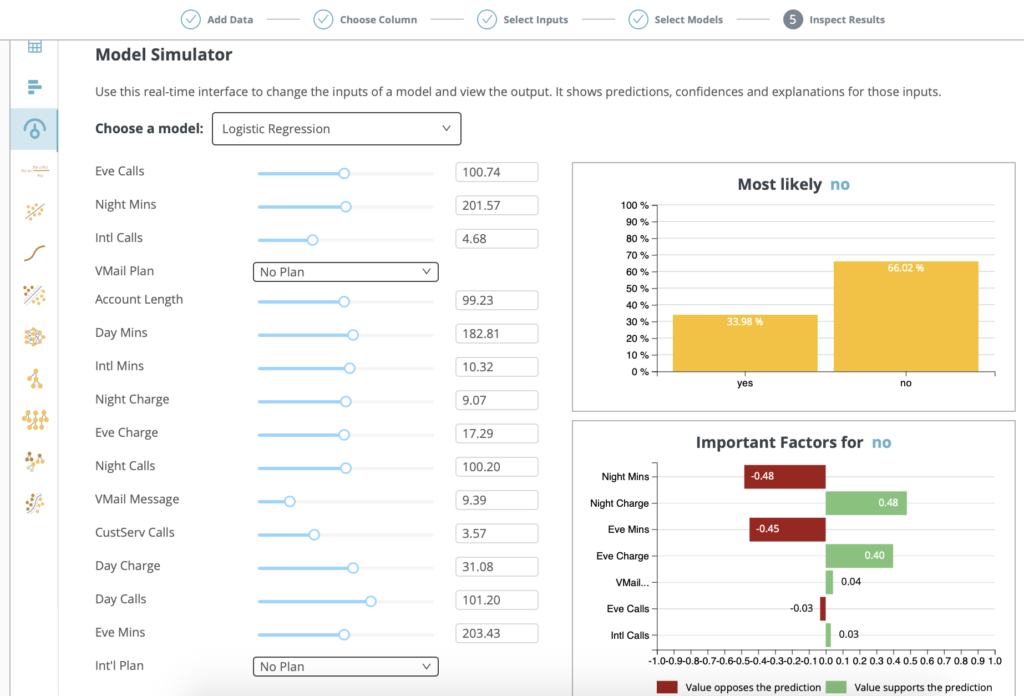
Model Simulator helps you understand how your model will behave under different sets of conditions.
Select a model and use the real-time interface to change the inputs of a model and view the output.
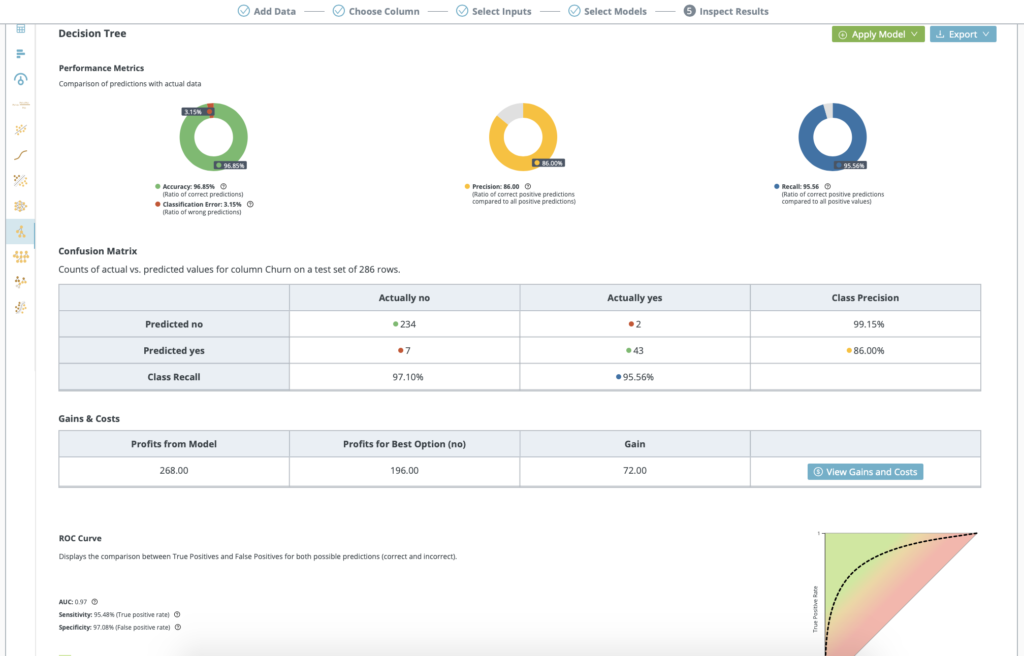
Explore the performance of each model
Calculate and assess business impact before deploying any models into production
View the performance metrics, confusion matrix, gains and costs, ROC curve and AUC.

Examine model values that define predictions.
Justify your work with automatically generated supporting materials
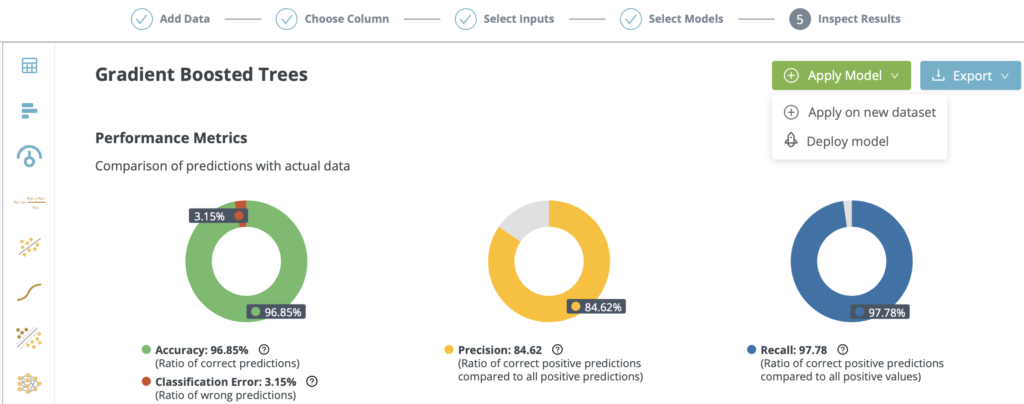
Score the model on a new dataset or deploy instantly, with or without a data science or DevOps team – AutoML for everyone.
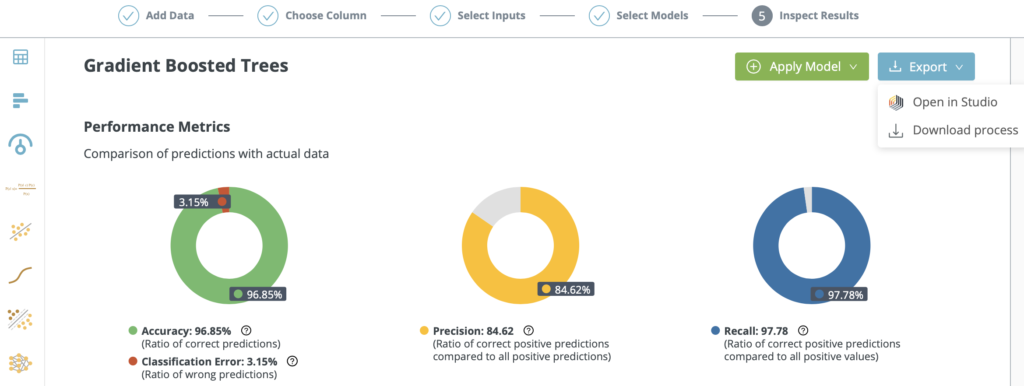
No Black Boxes
Open the process in RapidMiner Studio to fine tune or edit.
Note: To access data prep functionality or process building/edit functionality, a RapidMiner Studio license is required.
Feature List
System Requirements
| On-premise | Installed and running on your machine: Docker >= v18.09 docker-compose >= 1.23 |